Blog
Sequenced genomes per year
As part of building the case for creating our proposed CMOD resource, we wanted to know just how quickly the number of sequenced genomes was increasing. The thinking is that the more genomes are being sequenced, the more genomes there are that are going with virtually...
Creating a Centralized Model Organism Database (CMOD)
Model organism databases are great. They span a spectrum of model organisms as diverse as mouse, rat, fly, worm, zebrafish, yeast, and E. coli. And they fulfill key roles for their respective communities, from warehousing key genomic data, to providing query and...
[Fixed]Does it affect you? Black screen on recently updated Google Chrome.
Update (06/05): We have now deployed a workaround to BioGPS, so that Google Chrome users won't be affected by this bug. We have also reported this bug to Google Chrome team. If you still experience the issue, you might need a forced refresh on your browser. -- Update...
Molecular Predictor Repository? (not gene set repository)
I have a simple question. Say that I have the results from a gene expression analysis done in my laboratory or pulled from a public repository. Say the sample has something to do with cancer (or I think that it might). Say I read abou…
Data Chart Plugin Beta
How shall we find the concord of this discord? how to enlarge penis —William Shakespeare, A Midsummer Night's Dream Big news coming out of the Su Lab today! As you may know, we’ve been doing a lot of work recently on the presentation of our datasets stored in...
New BioGPS and MyGene.info Paper published
In this first post of the new year, we are happy to report that the update paper on BioGPS and MyGene.info is now published in the Nucleic Acids Research Database issue: This paper highlights the exciting updates on BioGPS since our first paper was published in...
GSoC recap for Crowdsourcing Biology team at TSRI
The Crowdsourcing Biology team at the Scripps Research Institute participated in the Google Summer of Code for the first time this year. Five students contributed to efforts to harness the power of community intelligence to advance biomedical science.
Introducing the Dataset Library
We're very excited to announce the addition of the Dataset Library to BioGPS! As I mentioned in my last blog post BioGPS now has thousands of datasets available for browsing. Providing this many datasets comes with some challenges, including making them easy to search...
Gene-disease annotation with Mobianga
Over the summer, an enterprising high school student named Nishant Mandapaty approached our research group about doing a project with us. He found us through the “Crowdsourcing Biology” group that we created for the Google Summer of Code program….
Results from the Cancer Biology game: The Cure
 |
| Building intelligent systems for biology |
Our research group has been exploring the concept of serious games for several months now. Aside from providing nerdy entertainment, our games collect (and distribute) biological knowledge from broad audiences of players. The hypothesis underlying this work is that, by capturing knowledge in forms suitable for computation, these games make it possible to build more intelligent programs.
As one step in testing this general hypothesis, on Sept. 7, 2012, we released a game called ‘The Cure’. The objective of this game is to build a better (more intelligent) predictor of breast cancer survival time based on gene expression and copy number variation information from tumor samples. We selected this particular objective to align with the SAGE Breast Cancer Prognosis challenge.
In this game, available at http://genegames.org/cure/, the player competes with a computer opponent to select the highest scoring set of five genes from a board containing 25 different genes. The boards are assembled in advance to include genes judged statistically ‘interesting’ using the METABRIC dataset provided for the SAGE Challenge.
Below is a game in progress. I’m on the bottom and my opponent, Barney, is on the top. We alternate turns selecting a card (a gene) from the board and adding it to our hand. When we each complete a 5 card hand, the round finishes and whoever has the most points wins. Scores are determined by using training data to automatically infer and test decision tree classifiers that predict survival time. The trees can use both RNA expression and CNV data for the selected genes to infer predictive rules. The better the gene set performs in generating predictive decision trees, the higher the score. When the player defeats their opponent, they move on to play another board. (Multiple players play each board.)
 |
| A game of the The Cure. Barney (the bad guy) is winning, I am looking at the CPB1 gene and, using the search feature, I have highlighted all genes that have the word cancer in any of their metadata in pink. |
As you can see to the right of the board, information from the Gene Ontology, RefSeq, and PubMed is provided through the game interface to aid players in selecting their genes. Players are also encouraged to make use of external knowledge sources (in addition to their own brains).
Promotion, players and play
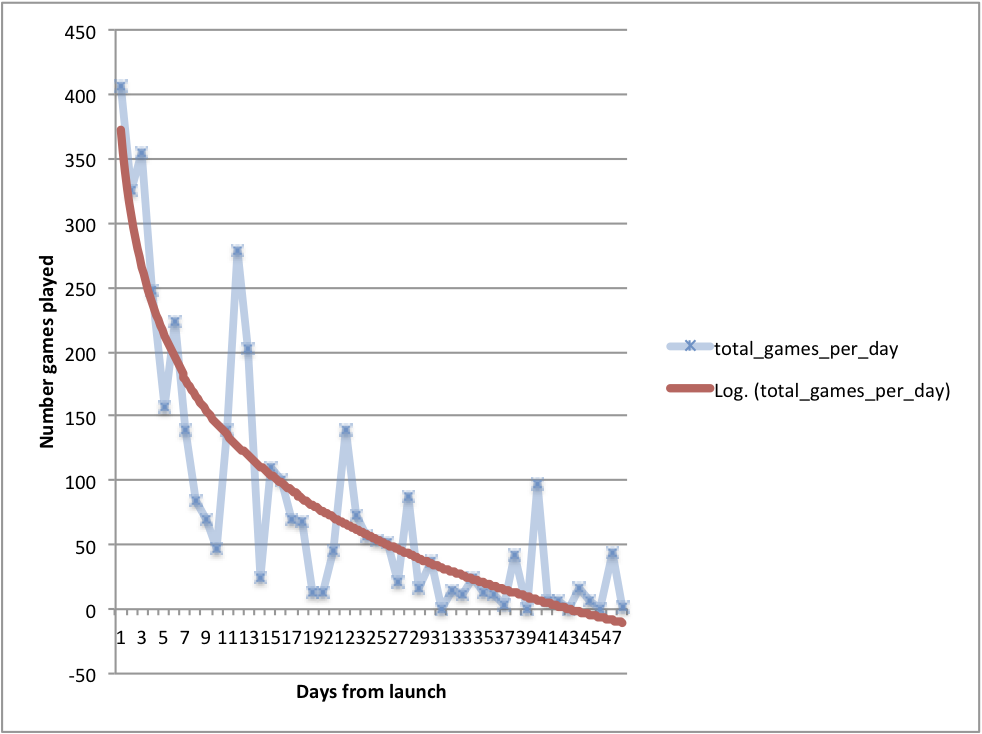 |
| Games played at The Cure since launch |
As of last Friday, Oct. 26, 2012 we have had 214 people register and have recorded 3,954 total games (including training games). The player demographics have remained stable with about 40% PhDs, nearly 50% declaring knowledge of cancer biology, and about 50% stating that they are biologists.
Predicting breast cancer prognosis
The data collected from game play includes information about the players (education, knowledge of cancer, profession) and the complete history of the genes that each player selects for each board that they play. While we are still considering methods for making use of this data (such as the Human Guided Forest), we used the following protocol to build a predictor to submit to the SAGE challenge.
- Filter out games from players that indicated no knowledge of cancer biology.
- Rank each gene according to the ratio of the number of times that it was selected by different players to the number of times that it appeared in any played game.
- Select the top 20 genes according to this ranking.
- Insert this 20 gene ‘signature’ into the ‘Attractor Metagene’ algorithm that has dominated the SAGE challenge. To do this, we kept all of the code related to the use of clinical variables unchanged, but replaced the genes selected by the Attractor team with the genes selected by our game players.
 |
| Game-selected genes |
The predictor generated with this protocol scored 69% correct on survival concordance index on the Sage challenge test dataset, just 3% behind the best submitted predictor and significantly above the median of hundreds of submitted models. (You can see the ranked results on the challenge leaderboard – search for team HIVE – and, with a free registration, you can inspect the model directly within the Synapse system operated by SAGE.)
In experiments conducted within the training dataset, we were able to consistently generate decision tree predictors of 10-year survival with an accuracy of 65% in 10-fold cross-validation using only genomic data (no clinical information). This was substantially better than classifiers produced using randomly selected genes (55%). Using an exhaustive search through the top 10 genes, we found 10 different unique gene combinations that, when aggregated, produced statistically significant (FDR < 0.05) indicators of survival within: (1) the training dataset used in the game, (2) a validation cohort from the same study, and (3) an independent validation set from a completely different study.
 |
| Final Results from METABRIC round of BCC challenge |
!! Update, the mode submitted using the The Cure data (Team HIVE) scored 0.70 on the official test dataset for the METABRIC round of this competition, putting it at #43 of of 171 submitted models !!
Conclusions
These early results from The Cure show clearly that biologists with knowledge that is relevant to cancer biology will play scientific games, and that combined with even basic analytical techniques, meaningful knowledge for inferring predictors of disease progression can be captured from their play. We suggest that this might open the door to a new form of ‘crowdsourcing’ that operates with much smaller, more specific crowds than are typically considered.
Data
The data collected from the game so far is available as an SQL dump in our repository. This is the entire database used to drive and track the game with the exception of personal information such as email and IP addresses.
Implementation
The code that operates The Cure is freely available on our BitBucket account. It consists of a Java server application (running in Tomcat) that handles database interaction, board generation, and integration with the WEKA machine learning library. WEKA is used to dynamically train and test decision trees (though we could easily use other models) while the game is running. The interface is almost entirely CSS and JavaScript that communicates with the server via JSON requests. We would be thrilled if some one wanted to use this code to build another classification game!
Trees
One aspect of the code-base that may be useful in a variety of different projects is the code that translates the Java objects that represent decision trees in WEKA into the Web-ready visualizations presented to the players. This is accomplished via server-side translation into a JSON structure that is rendered in the browser using code that builds on the D3 javascript visualization library.
Credits
Thanks to Max Nanis, Salvatore Loguercio, Chunlei Wu, Ian Macleod and Andrew Su for all of your help making The Cure. Thanks in particular to Max who authored 99% of everything you see when you play the game.
Barney
The opponent in The Cure came from a Wikipedia Commons image from the game “You have to Burn the Rope“. Thanks for sharing!
{kind=link}